Making a Go program run 1.7x faster with a one character change
If you read the title and thought “well, you were probably just doing something silly beforehand”, you’re right! But what is programming if not an exercise in making silly mistakes? Tracking down silly mistakes is where all the fun is to be had!
I’ll also state the usual benchmarking caveat up front: the 1.7x speedup was measured while running the program on my data on my computer, so take that number with a big old pinch of salt.
What does the program do?
codeowners is a Go program that prints out the owners for each file in a repository according to a set of rules defined in a GitHub CODEOWNERS file. A rule might say that all files ending in .go are owned by the @gophers team, or all files in the docs/ directory are owned by the @docs team.
When considering a given path, the last rule that matches wins. A simple but naive matching algorithm iterates backwards through the rules for each path, stopping when it finds a match. Smarter algorithms do exist, but that’s for another day. Here’s what the Ruleset.Match function looks like:
type Ruleset []Rule
func (r Ruleset) Match(path string) (*Rule, error) {
for i := len(r) - 1; i >= 0; i-- {
rule := r[i]
match, err := rule.Match(path)
if match || err != nil {
return &rule, err
}
}
return nil, nil
}Finding the slow bits with pprof and flamegraphs
The tool was a tad slow when running it against a moderately large repository:
$ hyperfine codeowners
Benchmark 1: codeowners
Time (mean ± σ): 4.221 s ± 0.089 s [User: 5.862 s, System: 0.248 s]
Range (min … max): 4.141 s … 4.358 s 10 runs
To see where the program was spending its time, I recorded a CPU profile with pprof. You can get a CPU profile generated by adding this snippet to the top of your main function:
pprofFile, pprofErr := os.Create("cpu.pprof")
if pprofErr != nil {
log.Fatal(pprofErr)
}
pprof.StartCPUProfile(pprofFile)
defer pprof.StopCPUProfile()Aside: I use pprof quite a lot, so I’ve got that code saved as a vscode snippet. I just type pprof, hit tab, and that snippet appears.
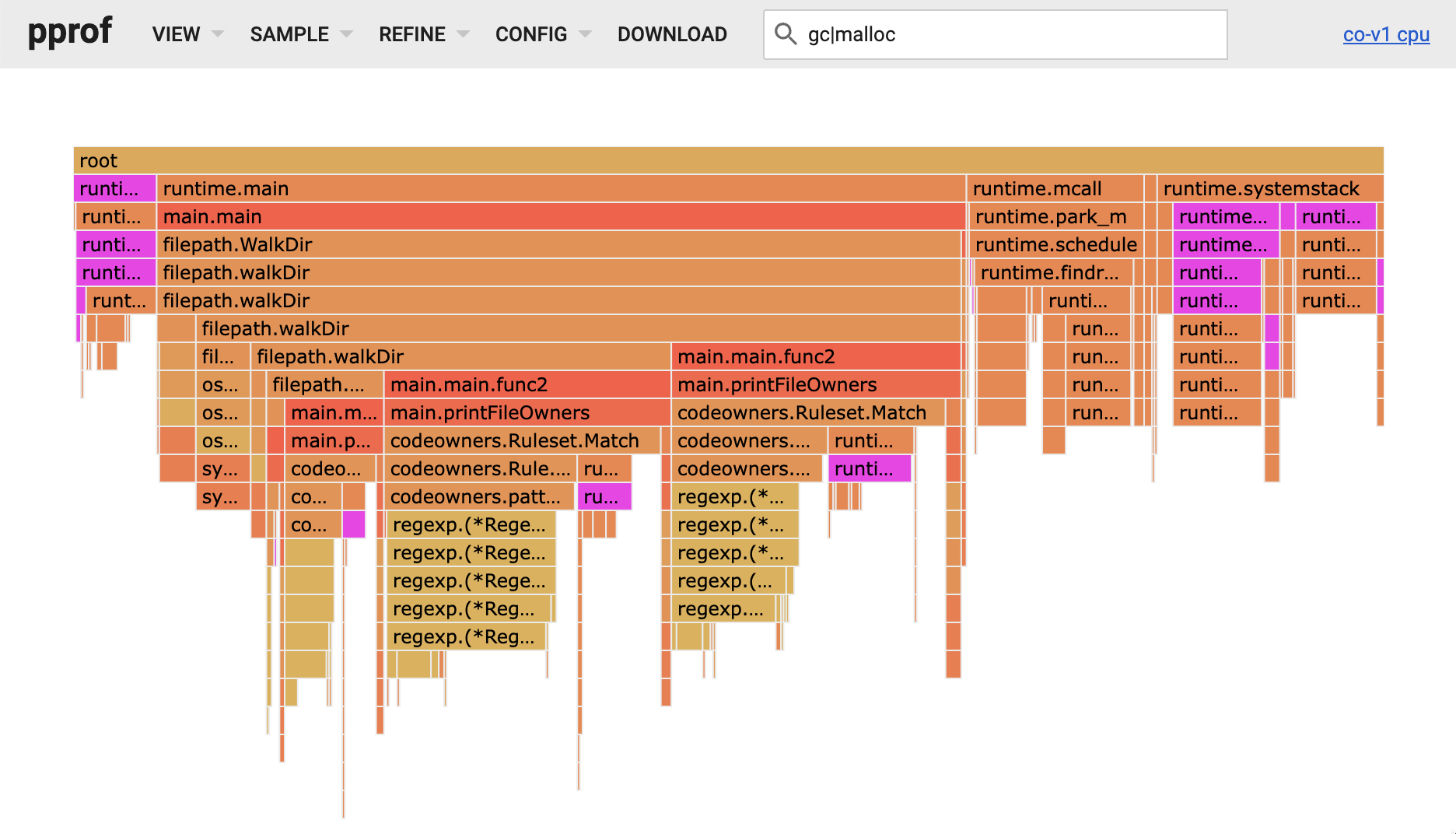
Go comes with a handy interactive profile visualisation tool. I visualised the profile as a flamegraph by running the following command then navigating to the flamegraph view in the menu at the top of the page.
$ go tool pprof -http=":8000" ./codeowners ./cpu.pprofAs I expected, most of the time was being spent in that Match function. The CODEOWNERS patterns are compiled to regular expressions, and the majority of the Match function’s time was spent in Go’s regex engine. But I also noticed a lot of time was being spent allocating and reclaiming memory. The purple blocks in the flamegraph below match the pattern gc|malloc, and you can see in aggregate they represent a meaningful part of the program’s execution time.
Hunting heap allocations with escape analysis traces
So let’s see if there are any allocations we can get rid of to reduce the GC pressure and time spent in malloc.
The Go compiler uses a technique called escape analysis to figure out when some memory needs to live on the heap. Say a function initialises a struct then returns a pointer to it. If the struct was allocated on the stack, the pointer that’s returned would become invalid as soon as the function returns and the corresponding stack frame is invalidated. In that case the Go compiler would determine that the pointer has “escaped” the function, and move the struct to the heap instead.
You can see these decisions being made by passing -gcflags=-m to go build:
$ go build -gcflags=-m *.go 2>&1 | grep codeowners.go
./codeowners.go:82:18: inlining call to os.IsNotExist
./codeowners.go:71:28: inlining call to filepath.Join
./codeowners.go:52:19: inlining call to os.Open
./codeowners.go:131:6: can inline Rule.Match
./codeowners.go:108:27: inlining call to Rule.Match
./codeowners.go:126:6: can inline Rule.RawPattern
./codeowners.go:155:6: can inline Owner.String
./codeowners.go:92:29: ... argument does not escape
./codeowners.go:96:33: string(output) escapes to heap
./codeowners.go:80:17: leaking param: path
./codeowners.go:70:31: []string{...} does not escape
./codeowners.go:71:28: ... argument does not escape
./codeowners.go:51:15: leaking param: path
./codeowners.go:105:7: leaking param content: r
./codeowners.go:105:24: leaking param: path
./codeowners.go:107:3: moved to heap: rule
./codeowners.go:126:7: leaking param: r to result ~r0 level=0
./codeowners.go:131:7: leaking param: r
./codeowners.go:131:21: leaking param: path
./codeowners.go:155:7: leaking param: o to result ~r0 level=0
./codeowners.go:159:13: "@" + o.Value escapes to heap
The output is a little noisy, but you can ignore most of it. As we’re looking for allocations, “moved to heap” is the phrase we should be concerned about. Looking back at the Match code above, the Rule structs are stored within the Ruleset slice, which we can be confident is already on the heap. And as a pointer to the rule is returned, no extra allocation should be necessary.
Then I saw it—by assigning rule := r[i], we copy the heap allocated Rule out of the slice onto the stack, then by returning &rule we create an (escaping) pointer to the copy of the struct. Fortunately, fixing this is easy. We just need to move the ampersand up a bit so we take a reference to the struct in the slice rather than copying it:
func (r Ruleset) Match(path string) (*Rule, error) {
for i := len(r) - 1; i >= 0; i-- {
- rule := r[i]
+ rule := &r[i]
match, err := rule.Match(path)
if match || err != nil {
- return &rule, err
+ return rule, err
}
}
return nil, nil
}
I did consider two other approaches:
- Changing
Rulesetfrom being[]Ruleto[]*Rule, which would mean we no longer need to explicitly take a reference to the rule. - Returning a
Rulerather than a*Rule. This would still copy theRule, but it should stay on the stack instead of moving to the heap.
However, both of these would have resulted in a breaking change as this method is part of the public API.
Anyway, after making that change we can see if it had the desired effect by getting a new trace from the compiler and comparing it to the old one:
$ diff trace-a trace-b
14a15
> ./codeowners.go:105:7: leaking param: r to result ~r0 level=0
16d16
< ./codeowners.go:107:3: moved to heap: rule
Success! The allocation is gone. Now let’s see how removing that one heap allocation affects performance:
$ hyperfine ./codeowners-a ./codeowners-b
Benchmark 1: ./codeowners-a
Time (mean ± σ): 4.146 s ± 0.003 s [User: 5.809 s, System: 0.249 s]
Range (min … max): 4.139 s … 4.149 s 10 runs
Benchmark 2: ./codeowners-b
Time (mean ± σ): 2.435 s ± 0.029 s [User: 2.424 s, System: 0.026 s]
Range (min … max): 2.413 s … 2.516 s 10 runs
Summary
./codeowners-b ran
1.70 ± 0.02 times faster than ./codeowners-a
As that allocation was happening for every single path that was being matched against, removing it got a 1.7x speedup in this instance. Not bad for a one character change.